Data Processing Approaches : Batch, Micro-batch, Streaming

When you need to process any amount of data, there are different types of data processing approaches like batch, stream processing and micro-batch. According to your use case, you can use these processing methods with the help of libraries such as Spark,Hadoop etc.
Before explaining 3 different processing methods, I would like to give some hints about the value of data processing. When you see the following diagram, please put attention to the interesting term; The diminishing value of data …
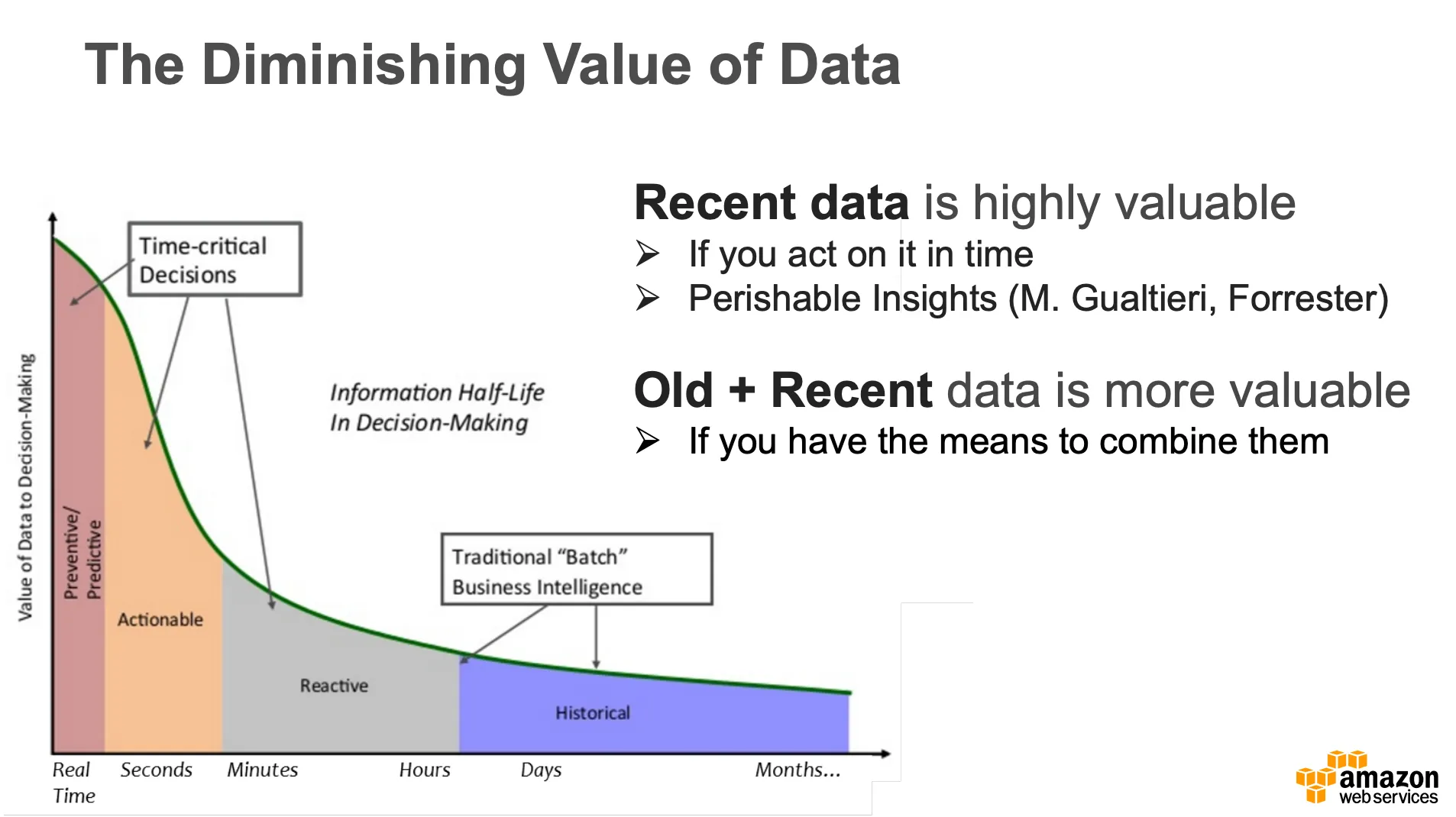
The diminishing value of data refers how much value is being created based on your processing approach. If analyse the most recent data and take a decision based on findings, it is highly valuable approach. Time critical decisions needs to be done within minutes. Let’s suppose you are looking for running shoes in order to replace with the old one. If you jump to any site which includes advertisement window, you are able to see running shoe advertisement what you are looking for.
Why this is important? Because you have an interest for running shoe.If advertisement comes multiple days later, you probably already buy the running shoe from another site. Thus, as a seller, you need to provide time-critical recommendations to make a value for your consumer.

What is batch processing?
Batch processing is a method which runs after the data arrives. Once store the data to storage layer, you make an analysis to create value from data. Let me give you an example. AWS S3 is a popular object storage layer within the cloud.

Once the data is stored, there are multiple options to process data, and one of option is using AWS EMR which provides multiple libraries such as Hadoop and Spark.In this case, you can process Petabyte level of data with batch processing… This approach is very useful for historical data analysis.Most of the companies use this approach and find valuable results from the data. Let me give you an example. A commerce company has multiple stores in the Europe and USA, they also have more than 100 product type. You have asked to distribute right number of product to the stores before the season, what you know is that each stores has different sell rates. What is the solution?
What you can do is to ask Analytics department to make some historical/batch data analysis to see what number of product sold in each stores in the previous sessions. Thus, you can make some forecast to distribute the right number of products

Real-time/Stream processing?
Stream processing is another method that you process data in real time. Once the data arrives to the messaging/queue platform, you are supposed to process data. Nowadays, companies are trying to use this strategy as much as possible in order to win the game!

One of good example is real-time welcome email. When the consumer sign-up to your website, you need to send a welcome email. From technical point, once the consumer sign-up, the event is published to messaging hub to be consumed by streaming processing engine in order to send an email.

The following picture give you an idea one of the example flow how real time processing is done for welcome email.

Micro-batch processing?
This processing approach is between stream processing and batch processing. What you need to do is to accumulate messages in small intervals(eg. minutes) and process them in the time windows. Let’s assume you are working in an e-commerce company and you have asked to prepare a solution to find out ; How many unique product is viewed within two minute time frames?. The following data flow explains exactly what you need. When consumer view any product, the data comes to Kafka to be consumed by Spark. Thus, Spark is accumulating messages within 2 minute windows and aggregate data based on productName. As a result, final table gives you what products are seen within 2 minute time frames.

Conclusion
As you see, there are different approaches to process the data. There is no certain recommendation to use any processing method. What you need to do is to define which approach creates best value of data. Most of the time, you need to use multiple processing methods to cover all different cases. Before talking about technology, I would recommend you to define processing approach, then you can easily find out the suitable library such as Spark Streaming, Kafka, Hadoop, Kinesis, Lambda etc…
